For a long time, we have advocated for an architecture that runs the Camunda workflow engine embedded into your own Java application, preferably via the Camunda Spring Boot Starter. But over time, we gradually moved away from this default recommendation in favor of a remote engine. In Zeebe, we don’t support embedding the engine at all.
In today’s blog post I want to explain the reasoning behind this move and why we recommend a remote engine. However, let’s first understand why the embedded engine was originally an appealing choice and observe what has changed over time. If you don’t care about the development over time, feel free to skip the history lesson and fast forward to the assessment of engine architectures.
A little bit of history on engine architecture recommendations
Looking back ten years to 2012, Jakarta EE application servers were popular, and Jakarta EE was still named J2EE. Most Java applications were deployed on such application servers. With Camunda, we consciously provided integration into those application servers by providing a container-managed engine, even for IBM Websphere, which was used in big corporate accounts. This integration was huge because it allowed developers to focus on developing their process solutions, without fiddling with how to configure the workflow engine, how to get transactions to work, etc. And we had great integrations: the workflow engine could easily leverage thread pools or transactions managed by the application server. At this time, the container-managed engine was the default.
But there were the Spring rebels fighting J2EE (recall the 2004 book that laid the groundwork for the success of Spring, J2EE Development without EJB.) Those folks used Spring and deployed on Tomcat. While there was a container-managed engine on Tomcat, it turned out that users did not like to fiddle with the Tomcat installation itself, but rather create one self-contained deployment (including the embedded workflow engine) they could put on any standard Tomcat. This worked much better in corporate environments, where a default Tomcat could be provisioned for you, but this Tomcat could not be customized.
While this was a favorite model, it bore some problems. For example, classloading when deploying your application next to Camunda’s web applications. It further left you with a wired mixture of configuring things in Tomcat, and others in the application. This all led to the rise of Spring Boot, where an application is completely self-contained. This also came in time with ideas around microservices and the rise of containers.
Around 2015, a group of enthusiastic people created the Spring Boot starter for Camunda, which made it into the official product already in 2017 given the big uptake by the community. Soon it became the default recommendation for new projects. A typical architecture looked like our greenfield stack recommendation:
But at the same time, the external task pattern emerged and quickly gained traction. One important factor of its success was that most process solutions at that time grew more complex and were no longer one self-contained application. Rather, they orchestrated remote endpoints and became part of a distributed system (for example in microservices architectures). In recent months, we made some effort to make external tasks the default programming model, even if we are still lacking some convenience. However, this can be built. Looking at Zeebe as the workflow engine within Camunda Cloud, it only knows the external task pattern and comes with great convenience for the developer.
Using external tasks you can easily provision the engine remotely, instead of embedding one. But why is this a good idea now?
The move to more distributed systems is flanked by trends like Docker, Kubernetes, and the overall move to the cloud. This is all interesting because it makes it easy to consume the resources your application needs as a service. Do you need the capability “relational database?” You simply provision one, either in the cloud or via one Docker command. Gone are the times when you had to install something manually. It is all automated, reproducible, easy, and reliable.
So when you need a capability “workflow engine,” you can also simply provision one. This is even easier than embedding it for most scenarios.
So in 2020, we defined a new distribution that focused solely on this use case: Camunda Run. The idea was a self-contained workflow engine that is highly configurable also in a Docker or Kubernetes environment, without the need to understand Java. This allows running the workflow engine as a service. Many bigger customers already do that for their internal development projects, as a kind of internal cloud. We are also providing our own cloud service by now (based on Zeebe).
The current recommendation
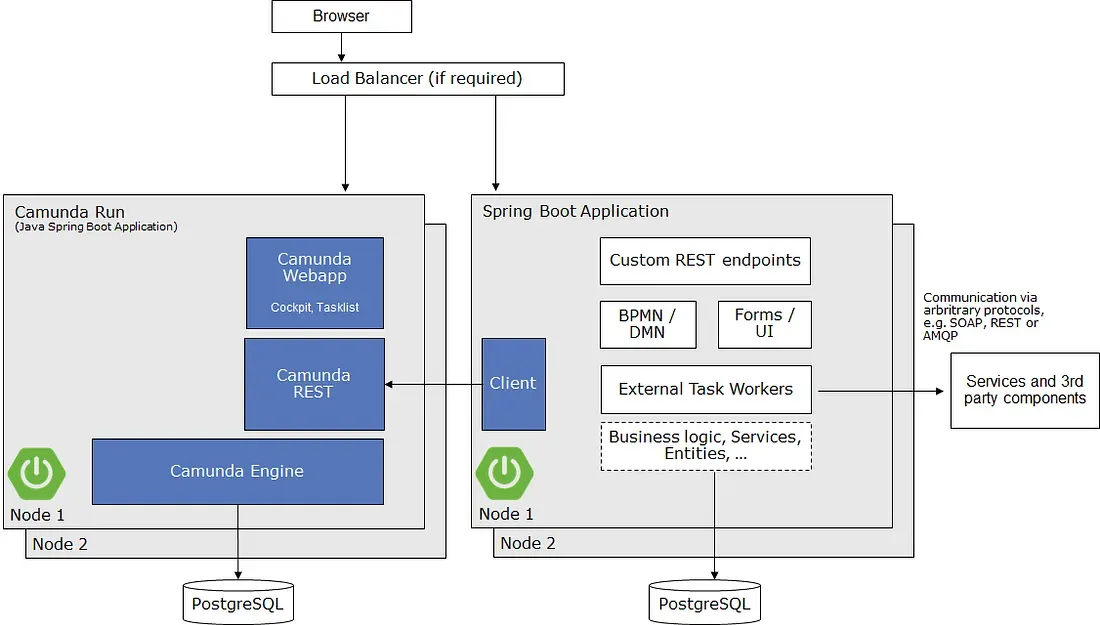
Now we are switching our default recommendation for Camunda Platform 7 towards using a remote engine, more concretely Camunda Run, as workflow engine, external tasks, and the REST API (typically wrapped into a client for your programming language). You might find this community extension helpful if you develop in Java. The upcoming greenfield stack recommendation will look like the following:
This stack is also close to what you would use in Camunda Cloud:
The remote engine approach makes it much easier to switch between the two stacks. You allow your organization to focus on one architectural style. And if you ever think about migrating from Camunda Platform 7 to Camunda Cloud someday in the future, this stack will make it much easier for you.
Next, let’s examine the pros and cons of the embedded engine in the light of today.
Weaknesses of the embedded engine
Let’s look at concrete issues we previously experienced with the embedded engine, exposing weaknesses of this model:
- No isolation between the engine and the application, meaning:
- Troubleshooting gets harder: In many support cases, all people involved needed significant time to investigate and understand the current architecture and configuration, which not only bound resources on both ends, but also delayed the problem resolution. Problems cannot easily be pinpointed to the engine or the application code, but can be anywhere in between.
- Libraries are mixed: The application automatically pulls in all dependencies of the workflow engine, probably even leading to version conflicts that are not always easy to resolve.
- Extensibility weakens stability: Applications embedding Camunda had manifold possibilities to influence the core engine behavior. This could affect the stability of the core engine or introduce vulnerabilities that are hard to diagnose.
- Rebuild and redeployment necessary: Workflow engine configuration changes or version updates (even patch versions) might require a complete rebuild and redeployment of the application.
- Complex configurations: While it is great that you can influence the thread pool of the engine, for example, it also makes things quite complicated and gives way too many options. And when running multiple engines, for example in bigger organizations, they might all be configured slightly differently.
- Harder to get started and more Java know-how required: If you are a Spring Boot pro, the Spring Boot Starter comes naturally to you. But in any other case, we found it can be confusing. It is much simpler to ask people to run a Docker container or start an engine in the cloud.
- No polyglot environments: Embedded engines can support just one programming language. In the case of Camunda, this language is Java. Modern architectures are much more polyglot and should support multiple languages.
- More load on developers: The embedded engine puts the burden of integrating and configuring the workflow engine itself onto the developer. As developers are really a rare species, you should better free their time as much as possible. Additionally, an embedded engine often cannot be configured from the outside to an extent your infrastructure folks would love to, e.g. to tweak it for production.
Benefits of a remote engine
The remote engine comes with a few benefits, mostly addressing the weaknesses above:
- Decoupling: The workflow engine is provisioned and configured independently of the application and process solution. Problems can be easily located on one of the components, and vulnerabilities are not transcending into other components.
- Improved scaling patterns: The workflow engine can be scaled independently of the application code. Camunda can optimize the performance of the core engine, as it has full control of what is running in this scope.
- Allow software as a service (SaaS): The workflow engine can be operated as a service for you, either in a public cloud (like Camunda Cloud) or probably as an in-house service (as customers of ours do). Still, you can develop your application locally or on-premise, as applications can remotely connect to the workflow engine.
- Easier getting started experience: You can provision an engine by a simple Docker command and don’t need to mess with configurations in your own application.
To share an anecdote, let’s look at a proof of concept that happened at a big car manufacturer two weeks ago. They used Apache Kafka and MongoDB. It was natural to them to have a Docker Compose file to start necessary resources, so it felt absolutely right to add two lines to start Camunda too. Then, they could distribute work. An infrastructure person looked into wiring Camunda with their PostgreSQL of choice and configuring some security stuff, while developers started right away at the same time to model and execute a BPMN process.
A remote engine requires you to use the external task pattern, which leads to further advantages simply by applying the external task pattern:
- Temporal decoupling: Your glue code (what we call workers) can be offline for a while, the work from the workflow engine will simply wait for it to come back. You get this temporal decoupling without the need to use a message broker.
- Polyglott architectures (non-Java environments): Java Delegates work only in Java, but external tasks allow all languages via leveraging REST.
- Decouple worker implementation: The worker is an own software component and not tied to the workflow engine at all. This means it can control many aspects itself. For example, if you need to execute a service task that takes hours (e.g. video transcoding), this is no problem. If you want to limit service invocations to one simultaneous call (e.g. for licensing reasons), you can easily control this.
Of course, you can also do external tasks with an embedded engine, basically just talking to your own application via REST. While this might be an interesting stepping stone to prepare your architecture for a remote engine, while actually no need to provision one, it is a relatively rare case in reality.
Some myths around remote engines
You might want to have a look at “How to write glue code without Java Delegates in Camunda Cloud,” debunking some common myths related to working with external tasks in the remote engine setup:
- You can still call your service endpoints via any protocol (e.g. REST, AMQP, Kafka).
- You can have all worker code in one Java application.
- The programming model looks surprisingly similar to Java Delegates when using Spring.
- Exception handling can still be delegated to the workflow engine.
- The performance overhead in terms of latency is not very big.
Challenges of a remote engine
Of course, there are also typical challenges developers face with the remote engine setup. Let’s look at those and how they are typically addressed.
- Convenience in programming model: Remote communication via REST or gRPC is less convenient for developers than simply using a client library in their programming language. This can be mitigated by providing proper client libraries that hide details of the remote communication, like Zeebe does for example for Spring, Java, or others. “How to write glue code without Java Delegates in Camunda Cloud” gives you a good overview of what I mean.
- Transactions in remote communication: With a remote engine, you cannot share transactions between your code and the workflow engine. I dedicated a blog post to this topic: “Achieving consistency without transaction managers.”
- Running a separate resource: The remote engine is an own resource, program, or container that you need to operate for your own application to run. Thanks to cloud services or Docker, this can be solved very easily nowadays and seems to be less of a problem than it was years ago. You could also simply download and unpack the workflow engine locally and start it up on your own computer, you just need Java installed.
- Writing unit tests: There is the specific challenge: that you want unit tests to run self-contained, without any dependency on the environment. This can generally be solved with the Testcontainers project, but for example Zeebe also provides a “mini engine” that can be run inflight in a JUnit test, eliminating this problem completely in the Java world. Refer to zeebe-process-test for details. Other programming languages might follow.
Summary
The remote engine mode will be the default for future process solutions. This gives you a lot of advantages and fits into modern ways to build software architecture. We want to provide the same convenience for developers and offer a comparable programming model for developers, especially in Camunda Cloud, but we also will catch up in Camunda Platform 7. I hope this blog post could assure you that this is not only a conscious but a very sound decision. If not, reach out to me or ask in the forum any time.
Bernd Ruecker is co-founder and chief technologist of Camunda as well as the author of Practical Process Automation with O’Reilly. He likes speaking about himself in the third person. He is passionate about developer-friendly process automation technology. Connect via LinkedIn. As always, he loves getting your feedback. Comment below or send him an email.
