Camunda Platform 8 reinvented the way an orchestration and workflow engine works. We applied modern distributed system concepts and can now even allow geo-redundant workloads, often referred to as multi-region active-active clusters. Using this technology, organizations can build resilient systems that can withstand disasters in the form of a complete data center outage.
For example, a recent customer project in a big financial institution connected a data center in Europe with one in the United States and this did not affect their throughput, meaning they can still run the same number of process instances per second. But before talking about multi-regions and performance, let’s disassemble this fascinating topic step-by-step in today’s blog post.
Many thanks to our distributed systems guru, Falko, for providing a ton of input about this topic, and my great colleague Nele for helping to get everything in order in this post.
Hang on — geo-redundant? Multi-region? Active-active?
First, let’s quickly explain some important basic terminology we are going to use in this post:
- Geo-redundancy (also referred to as geo-replication): We want to replicate data in a geographically distant second data center. This means even a massive disaster like a full data center going down will not result in any data loss. For some use cases, this becomes the de-facto standard as most businesses simply cannot risk losing any data.
- Multi-region: Most organizations deploy to public clouds and the public cloud providers name their different data centers a region. So in essence, deploying to two different regions makes sure; those deployments will end up in separate data centers.
- Availability zones: A data center, or a region, is separated into availability zones. Those zones are physically separated, meaning an outage because of technical failures is limited to one zone. Still, all zones of a region are geographically located in one data center.
- Active-active: When replicating data to a second machine, you could simply copy the data there, just to have it when disaster strikes. This is called a passive backup. Today, most use cases strive for the so-called active-active scenario instead, where data is actively processed on both machines. This makes sure you can efficiently use the provisioned hardware (and not keep a passive backup machine idle all the time).
- Zeebe: The workflow engine within Camunda Platform 8.
So let’s rephrase what we want to look at today: How to run a multi-region active-active Zeebe cluster (which then is automatically geo-redundant and geo-replicated). That’s a mouthful!
Resilience levels
Firstly, do you really need multi-region redundancy? To understand this better, let’s sketch the levels of resilience you can achieve:
- Clustering: You build a cluster of nodes in one zone. You can stand hardware or software failures of individual nodes.
- Multi-zone: You distribute nodes into multiple zones, increasing availability as you can now stand an outage of a full zone. Zone outages are very rare.
- Multi-region: You distribute nodes into multiple regions, meaning geographically distributed data centers. You will likely never experience an outage of a full region, as this might only happen because of exceptional circumstances.
So while most normal projects are totally fine with clustering, the sweet spot is multi-zone. Assuming you run on Kubernetes provided by one of the Hyperscalers, multi-zone is easy to set up and thus does not cause a lot of effort or costs. At the same time, it provides an availability that is more than sufficient for most use cases. Only if you really need to push this availability and need to withstand epic disasters do you need to go for multi-region deployments. I typically see this with big financial or telecommunication companies. That said, there might also be other drivers besides availability for a multi-region setup:
- Locality: Having a cluster spanning multiple regions, clients can talk to the nodes closest to them. This can decrease network latencies.
- Migration: When you need to migrate to another region at your cloud provider, you might want to gradually take workloads over and run both regions in parallel for some time to avoid any downtimes.
In today’s blog post, we want to unwrap Zeebe’s basic architecture to support any of those resilience scenarios, quickly describe a multi-zone setup, and also turn our attention to multi-region, simply because it is possible and we are regularly asked about it. Finally, we’ll explain how Zeebe scales and how we can turn any of those scenarios into an active-active deployment.
Replication in Zeebe
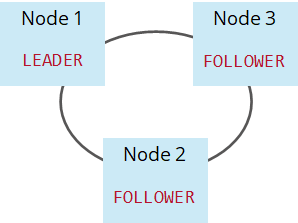
To understand how we can achieve resilience in Zeebe, you first need to understand how Zeebe does replication. Zeebe uses distributed consensus — more specifically the Raft Consensus Algorithm — for replication. There is an awesome visual explanation of the Raft Consensus Algorithm available online, so I will not go into all the details here. The basic idea is that there is a single leader and a set of followers. The most common setup is to have one leader and two followers, and you’ll see why soon.
When the Zeebe brokers start up, they elect a leader. Only the leader is allowed to write data. The data written by the leader is replicated to all followers. Only after a successful replication is the data considered committed and can be processed by Zeebe (this is explained in more detail in how we built a highly scalable distributed state machine). In essence, all (committed) data is guaranteed to exist on the leader and all followers all the time.
There is one important property you can configure for your Zeebe cluster — the replication factor. A replication factor of three means data is available three times, on the leader as well as replicated to two followers, as indicated in the image below.
A derived property is what is called the quorum. This is the number of nodes required to hold so-called elections. Those elections are necessary for the Zeebe cluster to select who is the leader and who is a follower. To elect a leader, at least round_down(replication factor / 2) + 1 nodes need to be available. In the above example, this means round_down(3/2)+1 = 2 nodes are needed to reach a quorum.
So a cluster with a replication factor of three can process data if at least two nodes are available. This number of nodes is also needed to consider something committed in Zeebe.
The replication factor of three is the most common, as it gives you a good compromise of the number of replicas (additional hardware costs) and availability (I can tolerate losing one node).
A sample failure scenario
With this in mind, let’s quickly run through a failure scenario, where one node crashes:
One node crashing will not affect the cluster at all, as it still can reach a quorum. Thus, it can elect a new leader and continue working. You should simply replace or restart that node as soon as possible to keep an appropriate level of redundancy.
Note that every Zeebe cluster with a configured replication factor has basic resilience built in.
Multi-zone Zeebe clusters
When running on Kubernetes in a public cloud, you can easily push availability further by distributing the different Zeebe nodes to different availability zones. Therefore, you can leverage multi-zone clusters in Kubernetes. For example, in Google Cloud (GCP) this would mean regional clusters (mind the confusing wording: a regional cluster is spread across multiple zones within one region). Then, you can set a constraint, that your Zeebe nodes, running as a stateful set, are all running in different zones from each other. Et voila, you added multi-zone replication:
From the Zeebe perspective, the scenario of a zone outage is now really the same as the one of a node outage. You can also run more than three Zeebe nodes, as we will discuss later in this post.
Multi-region Zeebe clusters
As multi-zone replication was so easy, let’s also look at something technically more challenging (reminding ourselves, that not many use cases actually require it): multi-region clusters.
You might have guessed it by now — the logic is basically the same. You distribute your three Zeebe nodes to three different regions. But unfortunately, this is nothing Kubernetes does out of the box for you, at least not yet. There is so much going on in this area that I expect new possibilities to emerge any time soon (just naming Linkerd’s multi-cluster communication with StatefulSets as an example).
In our customer project, this was not a show stopper, as we went with the following procedure that proved to work well:
- Spin up three Kubernetes clusters in different regions (calling them “west”, “central”, and “east” here for brevity).
- Set up DNS forwarding between those clusters (see solution #3 of Cockroach running a distributed system across Kubernetes Clusters) and add the proper firewall rules so that the clusters can talk to each other.
- Create a Zeebe node in every cluster using tweaked Helm charts. Those tweaks made sure to calculate and set the Zeebe broker ids correctly (which is mathematically easy, but a lot of fun to do in shell scripts;-)). This will lead to “west-zeebe-0” being node 0, “central-zeebe-0” being 1, and “east-zeebe-0” being 2.
Honestly, those scripts are not ready to be shared without hand-holding, but if you plan to set up a multi-region cluster, please simply reach out and we can discuss your scenario and assist.
Note that we set up as many regions as we have replicas. This is by design, as the whole setup becomes rather simple if:
- The number of nodes is a multiple of your replication factor (in our example 3, 6, 9, …).
- The nodes can be equally distributed among regions (in our example 3 regions for 3, 6, or 9 nodes).
Running Zeebe in exactly two data centers
Let’s discuss a common objection at this point: we don’t want to run in three data centers, we want to run it in exactly two! My hypothesis is that this yields from a time when organizations operated their own data centers, which typically meant there were only two data centers available. However, this changed a lot with the move to public cloud providers.
Truthfully, it is actually harder to run a replicated Zeebe cluster spanning two data centers than spanning three. This is because of the replication factor and using multiples — as you could see above. So in a world dominated by public cloud providers, where it is not a big deal to utilize another region, we would simply recommend replicating to three data centers.
Nevertheless, in the customer scenario, there was the requirement to run Zeebe in two regions. So we quickly want to sketch how this could be done. Therefore, we run 4 nodes to have two nodes in every region. This allows one node to go down and still guarantees a copy of all data in both regions. Therefore, three nodes are not enough to be able to deal with an outage of a whole region.
The following image illustrates our concrete setup:
There is one key difference to the three-region scenario: When you lose one region, an operator will need to jump in and take manual action. When two nodes are missing, the cluster has no quorum anymore (remember: replication factor 4 / 2 + 1 = 3) and cannot process data as visualized in the following diagram:
To get your cluster back to work, you need to add one more (empty) cluster node, having the Zeebe node id of the original node three (at the time of writing, the cluster size of Zeebe is fixed and cannot be increased on the fly, this is why you cannot simply add new nodes). The cluster automatically copies the data to this new node and can elect a new leader as the cluster is back online.
Adding this node is consciously a manual step to avoid a so-called split-brain situation. Assume that the network link between region one and region two goes down. Every data center is still operating but thinks the other region is down. There is no easy way for an automated algorithm within one of the regions to decide if it should start new nodes, but avoid starting new nodes in both regions. This is why this decision is pushed to a human operator. As losing whole regions is really rare, this is tolerable. Please note again that this is only necessary for the two-region scenario, not when using three regions (as they still have a quorum when one region is missing).
When the region comes back, you can start node 4 again, and then replace the new node 3 with the original one:
The bottom line is that using two regions is possible, but more complex than simply using three regions. Whenever you are not really constrained by the number of physical data centers available to you (like with public cloud providers), we recommend choosing a thoughtful number of regions.
Scaling workloads using partitions
So far, we simplified things a little bit. We were not building real active-active clusters, as followers do not do any work other than replicating. Also, we did not really scale Zeebe. Let’s look at this next.
Zeebe uses so-called partitions for scaling, as further explained in how we built a highly scalable distributed state machine. In the above examples, we looked at exactly one partition. In reality, a Camunda Platform 8 installation runs multiple partitions. The exact number depends on your load requirements, but it should reflect what was described above about multiples.
So a replication factor of three means we might run 12 partitions on six nodes, or 18 partitions on six nodes, for example. Now, leaders and followers of the various partitions are distributed onto the various Zeebe nodes, making sure those nodes are not only followers but also leaders for some of the partitions. This way, every node will also do “real work”.
The following picture illustrates this, whereas P1 — P12 stands for the various partitions:
Now, there is a round-robin pattern behind distributing leaders and their followers to the nodes. We can now leverage this pattern to guarantee geo-redundancy by adding the nodes to the various data centers in a clever round-robin too. As you can see above, for example in P1 the leader is in region 2, and the followers are in regions 1 and 3, so every data center has a copy of the data as described earlier. And this is also true for all other partitions. An outage will not harm the capability of the Zeebe cluster to process data. The following illustration shows what happens if region 3 goes down; the partitions only need to elect some new leaders:
And how does geo-redundancy affect performance?
Finally, let’s also have a quick look at how multi-region setups affect the performance and throughput of Zeebe. The elephant in the room is of course that network latency between geographically separate data centers is unavoidable. Especially if you plan for epic disasters, your locations should not be too close. Or if you want to ensure geographic locality, you might even want various data centers to be close to the majority of your customers, which might simply mean you will work with data centers all over the world. In our recent customer example, we used one GCP region in London and one in the US, Northern Virginia to be precise. The latency between those data centers is estimated to be roughly 80ms (according to https://geekflare.com/google-cloud-latency/), but latencies can also go further up to a couple of hundred milliseconds.
Spoiler alert: This is not at all a problem for Zeebe and does not affect throughput.
To add some spice to this, let’s quickly look at why this is a problem in most architectures. For example, in Camunda Platform 7 (the predecessor of the current Camunda Platform 8), we used a relational database and database transactions to store the workflow engine state. In this architecture, replication needs to happen as part of the transaction (at least if we need certain consistency guarantees, which we do) resulting in transactions that take a long time. Conflicts between transactions are thus more likely to occur, for example, because two requests want to correlate something to the same BPMN process instance. Second, typical resource pools for transactions or database connections might also end up being exhausted in high-load scenarios.
In summary, running Camunda Platform 7 geographically distributed is possible, but especially under high load, it bears challenges.
With the Camunda Platform 8 architecture, the engine does not leverage any database transaction. Instead, it uses a lot of ring buffers to queue things to do. And waiting for IO, like the replication reporting success, does not block any resource and further does not cause any contention in the engine. This is described in more detail in how we built a highly scalable distributed state machine.
Long story short: Our experiments clearly supported the hypothesis that geo-redundant replication does not affect throughput. Of course, processing every request will have higher latency. Or to put in other words, your process cycle times will increase, as the network latency is still there. However, it only influences that one number in a very predictable way. In the customer scenario, a process that typically takes around 30 seconds was delayed by a couple of seconds in total, which was not a problem at all. We have not even started to optimize for replication latency, but have a lot of ideas.
Summary
In this post, you could see that Zeebe can easily be geo-replicated. The sweet spot is a replication factor of three and replication across three data centers. In public cloud speak, this means three different regions. Geo-replication will of course add latency but does not affect throughput. Still, you might not even need such a high degree of availability and be happy to run in multiple availability zones of your data center or cloud provider. As this is built into Kubernetes, it is very easy to achieve.
Please reach out to us if you have any questions, specific scenarios, or simply want to share great success stories!
